
A OpenAI publicou recentemente um documento detalhando testes internos e descobertas sobre os seus modelos o3 e o4-mini (este último associado ao mais conhecido GPT-4o mini). Estes modelos mais recentes distinguem-se das primeiras versões do ChatGPT por capacidades avançadas de raciocínio e multimodalidade, incluindo gerar imagens, pesquisar na web, automatizar tarefas, recordar conversas antigas e resolver problemas complexos. Contudo, parece que estas melhorias trouxeram consigo efeitos secundários inesperados.
O que dizem os testes?
A OpenAI utiliza um teste específico, denominado PersonQA, para medir as taxas de "alucinação" dos seus modelos. Este teste fornece um conjunto de factos sobre pessoas para o modelo "aprender" e, em seguida, apresenta questões sobre essas mesmas pessoas. A precisão do modelo é avaliada com base nas suas tentativas de resposta.
No ano passado, o modelo o1 alcançou uma taxa de precisão de 47% e uma taxa de alucinação de 16%. A soma destes valores não perfaz 100%, o que sugere que as restantes respostas não foram nem precisas, nem alucinações. O modelo pode, por vezes, indicar que não sabe a resposta, não consegue localizar a informação, fornecer informação relacionada sem fazer afirmações concretas, ou cometer pequenos erros que não se classificam como alucinações completas.
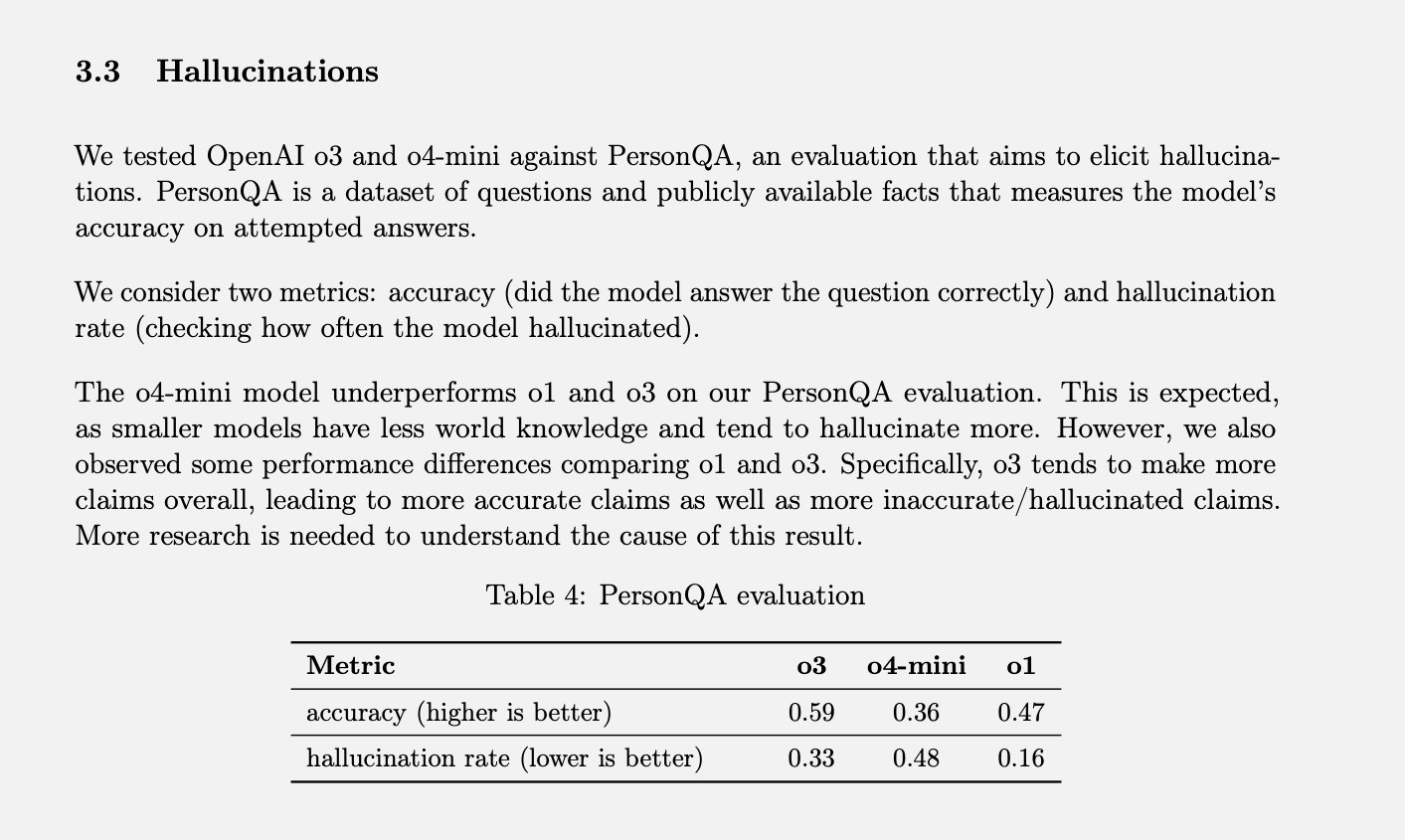
Quando os modelos mais recentes, o3 e o4-mini, foram submetidos a esta avaliação, apresentaram taxas de alucinação significativamente mais elevadas que o o1. Segundo a OpenAI, isto era, de certa forma, esperado para o o4-mini, por ser um modelo mais pequeno e com menos conhecimento do mundo, o que o levaria a gerar mais alucinações. Ainda assim, a taxa de 48% de alucinações atingida parece bastante elevada, considerando que se trata de um produto comercialmente disponível, utilizado para pesquisas na web e obtenção de informações e conselhos variados.
O o3, o modelo de maior dimensão, registou alucinações em 33% das suas respostas durante o teste. Embora supere o o4-mini, esta taxa representa o dobro da verificada no modelo o1. No entanto, o o3 também apresentou uma elevada taxa de precisão, que a OpenAI atribui à sua tendência geral para fazer mais afirmações. Portanto, se tem utilizado estes modelos mais recentes e notou um aumento nas respostas incorretas ou inventadas, não é apenas impressão sua.
O que são as "alucinações" da IA e porque acontecem?
Embora o termo "alucinação" em Inteligência Artificial (IA) seja comum, o seu significado nem sempre é claro. Ao utilizar qualquer produto de IA, seja da OpenAI ou de outra empresa, é quase garantido encontrar um aviso sobre a possibilidade de respostas imprecisas e a necessidade de verificação dos factos.
Informações incorretas podem ter diversas origens. Por vezes, um facto erróneo surge na Wikipédia ou utilizadores partilham informações falsas no Reddit, e essa desinformação pode infiltrar-se nas respostas da IA. Um exemplo notório foi quando o AI Overviews da Google sugeriu uma receita de pizza que incluía "cola não tóxica", informação que se descobriu ter origem numa piada numa discussão do Reddit.

Contudo, estes casos não são estritamente "alucinações", mas sim erros rastreáveis resultantes de dados incorretos ou má interpretação. As alucinações, por outro lado, ocorrem quando o modelo de IA faz uma afirmação sem qualquer fonte ou razão aparente. A OpenAI define este fenómeno como "uma tendência para inventar factos em momentos de incerteza". Outras figuras da indústria referem-se a isto como "preenchimento criativo de lacunas".
É possível induzir alucinações fazendo perguntas capciosas ao ChatGPT, como "Quais são os sete modelos do iPhone 16 disponíveis neste momento?". Como não existem sete modelos, é provável que o modelo forneça algumas respostas reais e invente os restantes para completar o pedido.
Como o treino influencia as respostas
Os chatbots como o ChatGPT não são treinados apenas com os dados da internet que informam o conteúdo das suas respostas, mas também sobre "como responder". São expostos a milhares de exemplos de perguntas e respostas ideais para encorajar o tom, a atitude e o nível de polidez adequados.
Esta parte do processo de treino leva o modelo de linguagem (LLM) a parecer concordar ou compreender o utilizador, mesmo quando o resto da sua resposta contradiz essas afirmações. É possível que este treino contribua para a frequência das alucinações, pois uma resposta confiante que aborda a questão pode ter sido reforçada como um resultado mais favorável do que uma resposta que admite desconhecimento.
Para nós, parece óbvio que inventar informações é pior do que admitir não saber a resposta. No entanto, os LLMs não "mentem" – nem sequer compreendem o conceito de mentira. Não desenvolvem mal-entendidos nem recordam mal a informação como os humanos. Eles não possuem conceitos de precisão ou imprecisão; simplesmente preveem a próxima palavra numa frase com base em probabilidades calculadas a partir dos dados de treino. Felizmente, na maioria dos casos, a informação mais comum tende a ser a correta, o que faz com que as reconstruções muitas vezes reflitam factos precisos.
Estes modelos são alimentados com vastas quantidades de informação da internet, sem que lhes seja indicado o que é bom ou mau, preciso ou impreciso. Não possuem conhecimento fundamental prévio ou princípios subjacentes para os ajudar a filtrar a informação. Tudo se resume a um jogo de números: os padrões de palavras que ocorrem com mais frequência num determinado contexto tornam-se a "verdade" do LLM.
O Desafio da OpenAI e o Futuro
O problema reside no facto de a OpenAI ainda não saber exatamente porque é que estes modelos avançados tendem a alucinar com maior frequência. Talvez com mais investigação se consiga compreender e corrigir o problema, mas também existe a possibilidade de o caminho não ser tão simples. A empresa continuará, sem dúvida, a lançar modelos cada vez mais "avançados", e existe o risco de as taxas de alucinação continuarem a aumentar.
Neste cenário, a OpenAI poderá ter de procurar uma solução a curto prazo, enquanto prossegue a investigação sobre a causa fundamental. Afinal, estes modelos são produtos comerciais que precisam de estar num estado utilizável. Uma ideia especulativa seria criar um produto agregado – uma interface de chat com acesso a múltiplos modelos da OpenAI.
Quando uma consulta exigisse raciocínio avançado, recorreria ao GPT-4o; quando o objetivo fosse minimizar alucinações, poderia usar um modelo mais antigo como o o1. Talvez fosse até possível utilizar diferentes modelos para diferentes elementos de uma única consulta, com um modelo adicional a agregar tudo no final, incorporando talvez um sistema de verificação de factos.
Contudo, o objetivo principal não é apenas aumentar as taxas de precisão, mas sim diminuir as taxas de alucinação. Isto implica valorizar tanto as respostas que admitem "não sei" como as que fornecem a resposta correta.
Ainda não se sabe qual será a abordagem da OpenAI ou quão preocupados estão os seus investigadores com esta tendência crescente. O que é certo é que mais alucinações são prejudiciais para os utilizadores finais, aumentando as oportunidades de sermos induzidos em erro sem nos apercebermos. Se utiliza frequentemente LLMs, não há necessidade de parar, mas não deixe que o desejo de poupar tempo se sobreponha à necessidade crucial de verificar os factos. Verifique sempre!














Nenhum comentário
Seja o primeiro!