
Após a revelação oficial, que já detalhámos anteriormente aqui no TugaTech, a Google começou a divulgar os detalhes técnicos que sustentam as suas afirmações de liderança. Se o anúncio focou nas capacidades gerais, os números agora apresentados pela DeepMind contam a história de um salto significativo no raciocínio e na multimodalidade.
Para os entusiastas que vivem de dados e comparações, o Gemini 3 não desilude, estabelecendo novos recordes e desafiando diretamente a concorrência do GPT-5.1 e do Claude Sonnet 4.5. Vamos mergulhar nos resultados.
Um novo rei na LMArena
O indicador mais imediato do impacto deste modelo é a sua pontuação na LMArena Leaderboard. O Gemini 3 alcançou uma pontuação Elo recorde de 1501, colocando-o no topo da tabela. Este valor é um indicador forte da preferência humana e da capacidade do modelo em lidar com uma variedade de instruções complexas em comparação com os seus pares.
Mas a Google não se ficou por aqui e apresentou resultados em testes mais específicos e rigorosos:
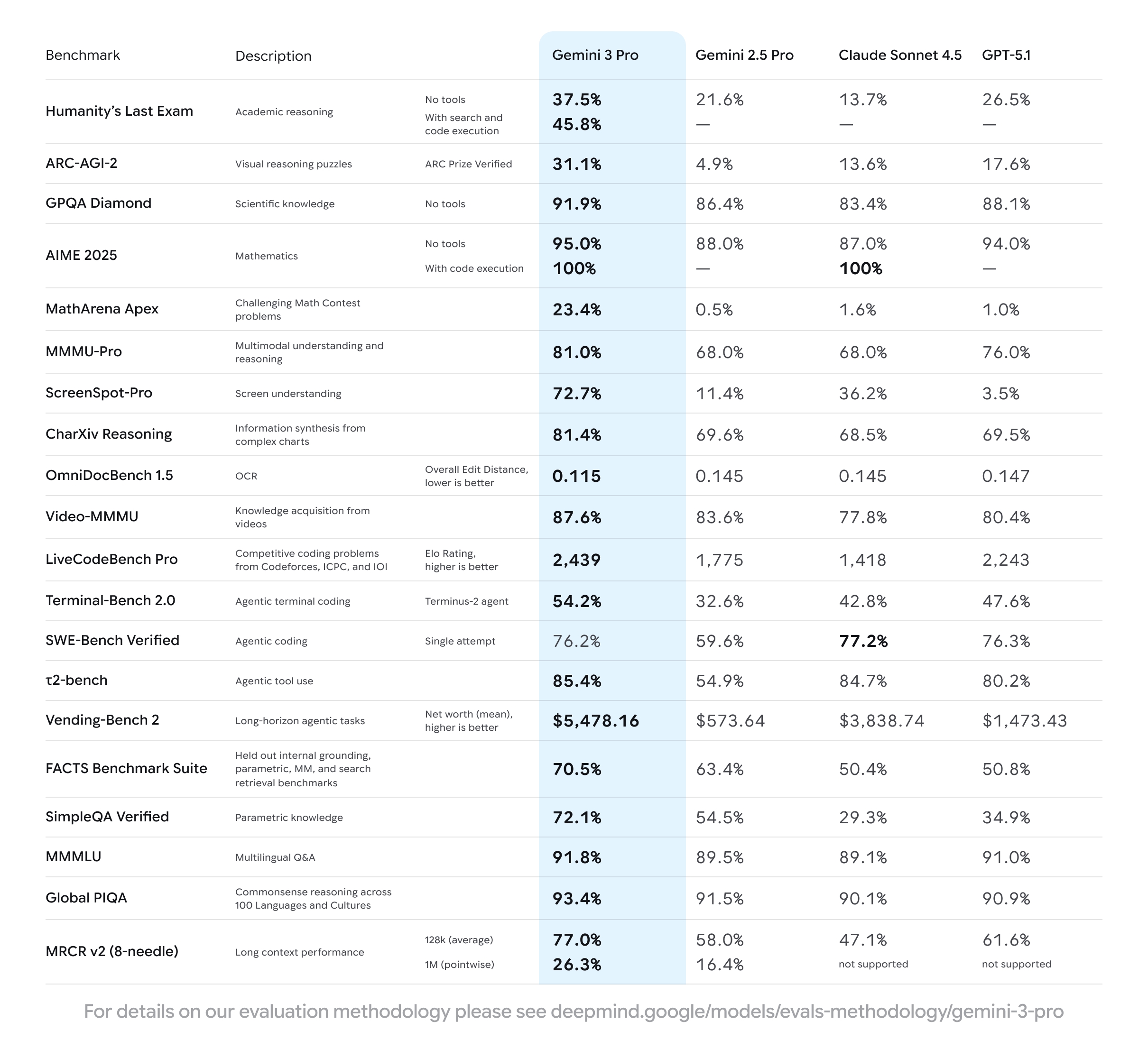
Humanity’s Last Exam: O modelo base obteve 37.5%.
GPQA Diamond: Uma pontuação impressionante de 91.9%, demonstrando uma capacidade de resposta a perguntas de nível de pós-graduação.
MathArena Apex: Alcançou o estado da arte (SOTA) com 23.4%, destacando a sua evolução no raciocínio matemático.
SimpleQA Verified: Focado na precisão factual, o modelo obteve 72.1%, outro resultado de topo.
O poder do "Deep Think"
A grande surpresa nos benchmarks, no entanto, reside no novo modo Gemini 3 Deep Think. Esta variante foi desenhada especificamente para tarefas que exigem um raciocínio mais profundo e prolongado, e os números refletem essa especialização.
Quando comparado com a versão Pro normal, o modo Deep Think eleva a fasquia:
Sobe para 41% no Humanity’s Last Exam.
Atinge 93.8% no GPQA Diamond.
No ARC-AGI-2 (com execução de código), alcança 45.1%.
Apesar deste aumento de desempenho e complexidade de processamento, a Google manteve a janela de contexto massiva de 1 milhão de tokens, garantindo que o modelo consegue "ler" e analisar vastas quantidades de informação sem perder o fio à meada.
Domínio Multimodal e a questão da Programação
Onde o Gemini 3 parece brilhar com maior intensidade é na sua capacidade multimodal — a habilidade de entender e relacionar texto, imagem e vídeo simultaneamente.
MMMU-Pro: 81%
Video-MMMU: 87.6%
Estes valores sugerem que o modelo está particularmente apto para analisar conteúdos visuais complexos, o que explica a sua integração imediata no Modo IA da Pesquisa Google para criar experiências visuais imersivas.
No entanto, há um campo onde a batalha continua renhida. No SWE-bench Verified, o teste padrão para capacidades de codificação e programação, o Gemini 3 Pro obteve 76.2%. Embora seja uma pontuação extremamente respeitável, a própria Google nota que fica ligeiramente abaixo dos resultados apresentados pelo GPT-5.1 da OpenAI e pelo Claude Sonnet 4.5 da Anthropic.
Para os programadores que queiram testar estas capacidades por si mesmos, o modelo já está disponível numa vasta gama de plataformas, incluindo o Google AI Studio, Vertex AI e GitHub, bem como na nova plataforma de desenvolvimento de agentes, a Google Antigravity.










Nenhum comentário
Seja o primeiro!