
A Google anunciou o Gemma 3n, a mais recente evolução dos seus modelos de inteligência artificial abertos, representando um salto significativo em capacidade e eficiência. Após uma antevisão no Google I/O no mês passado, a versão completa está agora disponível para programadores e entusiastas que a queiram executar diretamente no seu próprio hardware.
Ao contrário do Gemini, o poderoso modelo proprietário e fechado da Google, a família Gemma foi concebida para ser aberta. Isto significa que os programadores podem descarregar, modificar e adaptar os modelos às suas necessidades específicas, promovendo a inovação em toda a comunidade tecnológica.
A grande novidade é que o Gemma 3n consegue agora processar nativamente uma variedade de inputs, como imagens, áudio e vídeo, para gerar respostas em texto. Além disso, foi otimizado para ser incrivelmente eficiente, capaz de funcionar em dispositivos com apenas 2 GB de memória RAM, prometendo um desempenho superior em tarefas como programação e raciocínio lógico.
As grandes novidades do Gemma 3n
A Google destacou um conjunto de melhorias que tornam o Gemma 3n uma ferramenta poderosa e versátil:
Multimodal por natureza: O modelo suporta de forma nativa a entrada de imagens, áudio, vídeo e texto, gerando sempre saídas em formato de texto.
Otimizado para dispositivos: Projetado com um foco na eficiência, o Gemma 3n está disponível em dois tamanhos principais: E2B e E4B. Embora os seus parâmetros brutos sejam de 5 e 8 mil milhões, respetivamente, inovações na arquitetura permitem que funcionem com uma pegada de memória comparável a modelos tradicionais de 2 e 4 mil milhões de parâmetros, necessitando de apenas 2 GB (E2B) e 3 GB (E4B) de memória.
Arquitetura inovadora: No seu núcleo, o Gemma 3n apresenta componentes novos como a arquitetura MatFormer, que oferece flexibilidade computacional, os Per Layer Embeddings (PLE) para eficiência de memória, e novos codificadores de áudio e visão baseados no MobileNet-v5, otimizados para uso local.
Qualidade melhorada: O modelo oferece melhorias de qualidade significativas no suporte multilingue (140 idiomas para texto e compreensão multimodal de 35 idiomas), bem como em matemática, programação e raciocínio.
Arquitetura Matryoshka e performance de topo
A eficiência do Gemma 3n reside numa nova arquitetura que a Google apelidou de MatFormer. A analogia usada é a de uma boneca russa Matryoshka: um modelo maior contém uma versão mais pequena e totalmente funcional no seu interior.
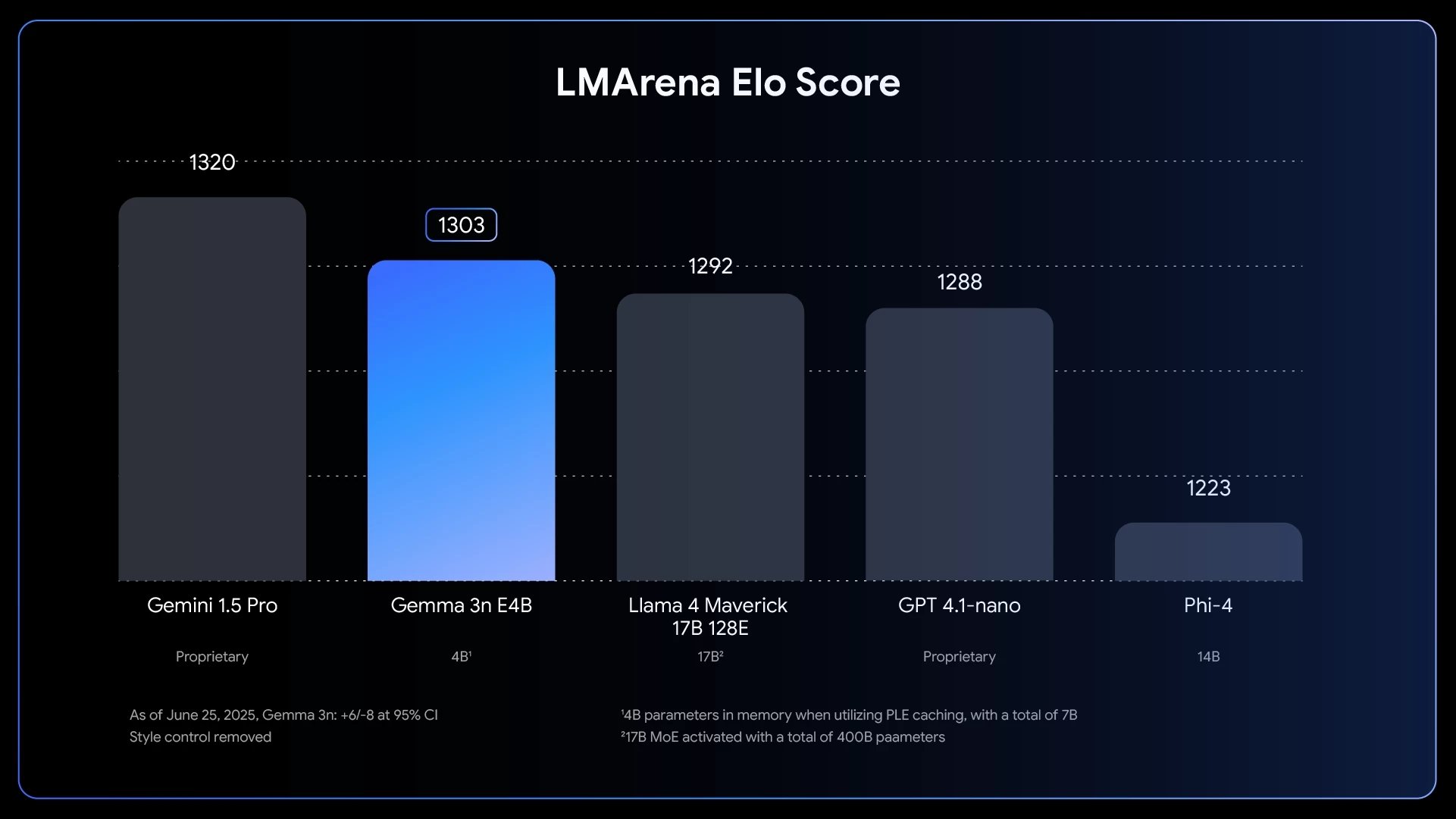
Esta abordagem engenhosa permite que um único modelo funcione em diferentes "tamanhos" para se adaptar a diferentes tarefas e capacidades de hardware. Em termos de performance, o modelo maior, E4B, já fez história ao ser o primeiro modelo com menos de 10 mil milhões de parâmetros a ultrapassar a pontuação de 1300 no conceituado benchmark LMArena.
Capacidades de áudio e vídeo em detalhe
As novas capacidades de áudio do Gemma 3n permitem a conversão de voz para texto e tradução diretamente no dispositivo, utilizando um codificador que processa a fala com um detalhe impressionante.
No campo da visão, o sistema é alimentado por um novo codificador chamado MobileNet-V5, que se revelou muito mais rápido e eficiente que o seu antecessor. Esta tecnologia permite processar vídeo a uma velocidade de até 60 frames por segundo (FPS) num dispositivo Google Pixel, abrindo portas a análises de vídeo em tempo real.
Como experimentar o Gemma 3n
Para os interessados em explorar o potencial do novo modelo, a Google tornou o acesso bastante simples. O Gemma 3n já está disponível em plataformas populares como o Hugging Face e o Kaggle. É também possível experimentar as suas capacidades diretamente no Google AI Studio. Para mais detalhes técnicos, pode consultar o anúncio oficial no blog da Google.














Nenhum comentário
Seja o primeiro!