
O crescimento exponencial da inteligência artificial generativa fez disparar os custos com hardware e memória em todo o mundo. Para contrariar esta tendência e disponibilizar soluções menos exigentes a nível de recursos, a Google anunciou o lançamento do Gemma 4 12B, um novo modelo de ia local concebido para preencher o espaço intermédio da sua linha de produtos lançada no início do ano. Esta versão destaca-se por ser leve o suficiente para ser executada em computadores portáteis convencionais de consumo, sem comprometer a qualidade dos resultados.
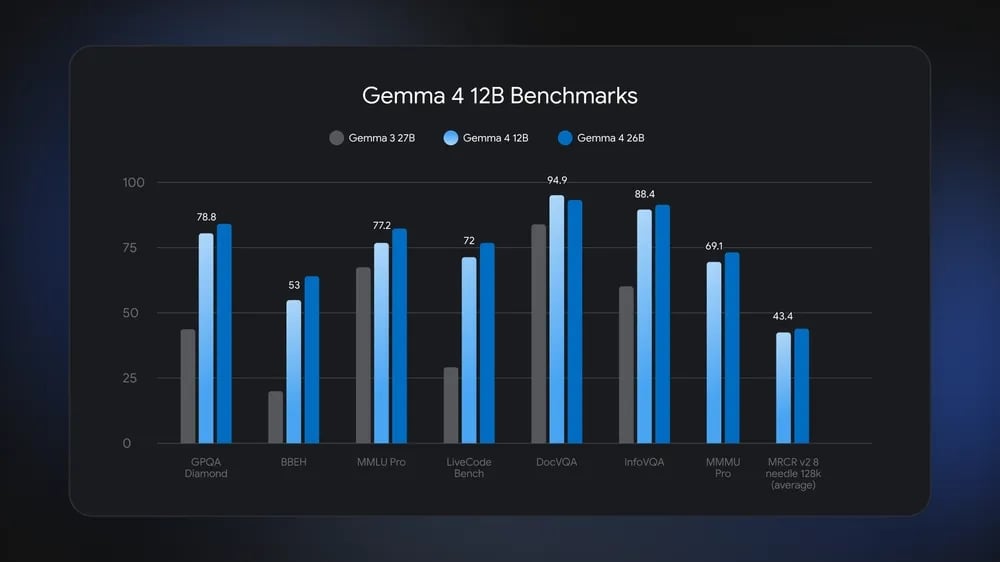
De acordo com as informações partilhadas pela Google na apresentação do modelo, os utilizadores apenas necessitam de um computador equipado com 16 gigabytes de memória RAM ou VRAM para colocar os 12 mil milhões de parâmetros a funcionar. Este requisito representa cerca de metade do consumo de memória exigido pela versão MoE de 26 mil milhões de parâmetros. No entanto, os testes de desempenho demonstram que a capacidade de resposta do novo modelo é praticamente equivalente à do seu irmão maior, eliminando a necessidade de adquirir aceleradores dispendiosos que chegam a custar milhares de euros.
Eficiência sem necessidade de hardware dispendioso
A nova variante de 12 mil milhões de parâmetros foi desenhada especificamente para processar raciocínios complexos em várias etapas e fluxos de trabalho baseados em agentes, tarefas que anteriormente exigiam as versões mais pesadas da família Gemma. Para alcançar maior velocidade e eficiência mesmo com uma contagem de parâmetros reduzida, a empresa integrou de forma nativa os denominados Multi-Token Prediction (MTP) drafters. Esta tecnologia aproveita os ciclos de processamento não utilizados para calcular os tokens futuros, garantindo um desempenho superior logo a partir da instalação.
Arquitetura multimodal simplificada e maior velocidade
Outro dos grandes avanços deste modelo intermédio reside na abordagem à multimodalidade. Ao contrário da maioria dos modelos generativos tradicionais, que utilizam codificadores dedicados para processar entradas de áudio ou imagem antes de as enviar para o modelo de linguagem principal, o Gemma 4 12B introduz um módulo de incorporação simplificado para conteúdos visuais. Este sistema recorre a multiplicação de matriz única e posicionamento espacial para transmitir os dados diretamente, reduzindo de forma drástica a latência e o consumo de memória. No caso do áudio, o sinal bruto é projetado diretamente nos mesmos vetores utilizados para os tokens de texto, eliminando qualquer processo de codificação intermediário.
Os utilizadores interessados em testar o Gemma 4 12B podem fazê-lo de forma imediata e sem necessidade de descarregar ficheiros através de ferramentas conhecidas como o LM Studio ou a Google AI Edge Gallery. Para quem prefere a execução local e possui os requisitos mínimos de memória, os pesos do modelo já se encontram disponíveis para download nas plataformas Kaggle e Hugging Face, ocupando um espaço ligeiramente inferior a 18 gigabytes.














Nenhum comentário
Seja o primeiro!