
Qualquer programador sabe que um código gerado por inteligência artificial pode parecer perfeito no ecrã, mas falhar redondamente quando aplicado numa aplicação complexa. Para separar o trigo do joio, de acordo com o site oficial, a Google introduziu o Android Bench, uma nova ferramenta de avaliação desenhada para colocar a performance dos grandes modelos de linguagem à prova diretamente no seu sistema operativo.
Testes baseados no mundo real
Em vez de pedir aos modelos para escreverem programas genéricos e básicos, este novo ranking foca-se em desafios concretos retirados de projetos de código aberto reais presentes no GitHub, com a particularidade de selecionar apenas repositórios com mais de 500 estrelas. O objetivo é perceber se a tecnologia consegue efetivamente corrigir falhas ou adicionar funcionalidades de uma forma que seja tecnicamente viável para uma base de código profissional.
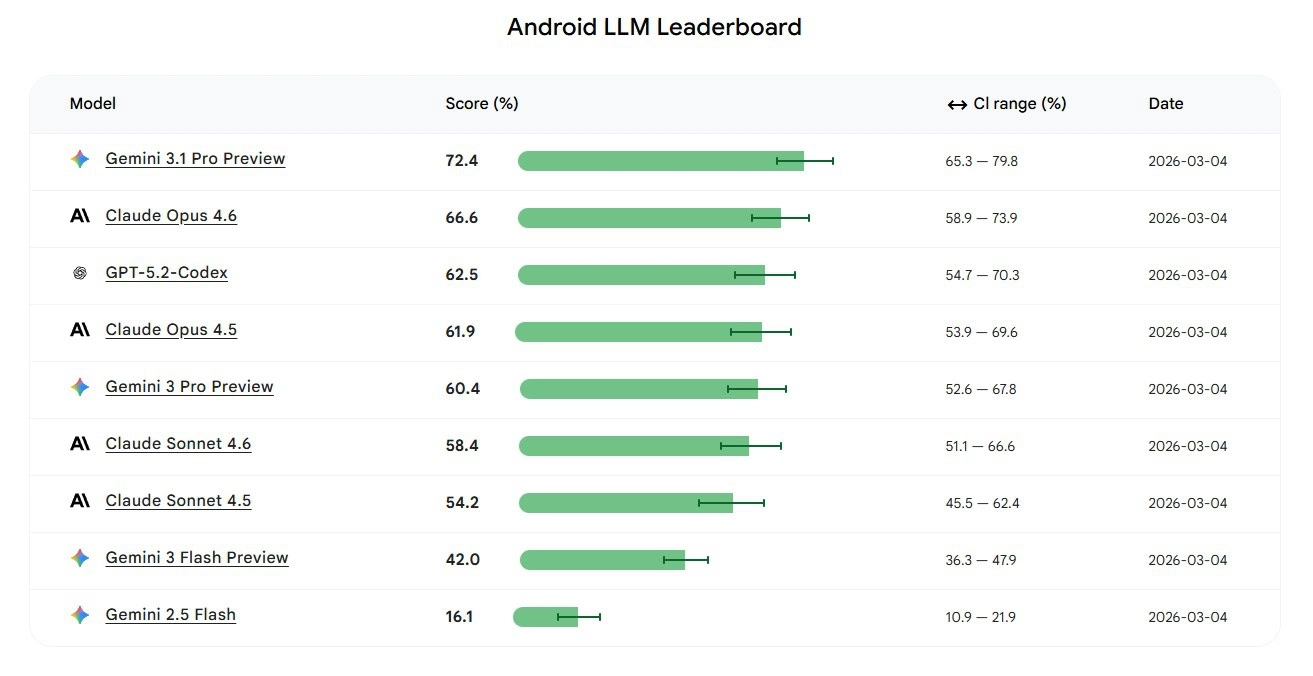
A primeira ronda de testes revelou uma discrepância substancial entre os melhores e os piores modelos, com as taxas de sucesso a variarem entre uns modestos 16% e um limite máximo muito mais impressionante em torno dos 72%.
A liderança do Gemini e o impacto no desenvolvimento
Neste arranque de março de 2026, o modelo Gemini 3.1 Pro Preview assume o primeiro lugar da tabela, ao concluir com êxito 72,4% das tarefas propostas. Logo atrás na perseguição encontram-se o Claude Opus 4.6, com 66,6%, e o GPT-5.2-Codex a registar 62,5%.
Apesar de não ser uma surpresa ver a criação da gigante tecnológica a brilhar na sua própria plataforma, a existência deste nível de transparência é uma grande vitória para a comunidade. Ao disponibilizar publicamente a metodologia, os conjuntos de dados e as ferramentas de teste, a iniciativa procura fechar o fosso entre o conceito teórico e a qualidade do código, convidando toda a indústria a afinar os seus sistemas para o desenvolvimento móvel e deixando as promessas de marketing para trás.














Nenhum comentário
Seja o primeiro!