
Uma das funcionalidades mais pedidas pelos utilizadores do Google Chrome está finalmente a chegar: a capacidade de copiar texto diretamente de documentos PDF que foram digitalizados. Esta novidade promete acabar com uma frustração antiga para muitos.
Fim da frustração com documentos digitalizados no Chrome
Quem nunca abriu um PDF no Chrome e descobriu, com desânimo, que o documento não passava de uma imagem digitalizada, impedindo qualquer interação com o texto? Nestes casos, não era possível selecionar, copiar ou sequer utilizar a função de pesquisa (Ctrl + F) para encontrar palavras específicas. Era uma limitação particularmente irritante, transformando tarefas simples numa verdadeira dor de cabeça.
Felizmente, uma atualização recente ao visualizador de PDFs integrado no Chrome veio robustecê-lo significativamente. O navegador consegue agora "ler" e distinguir o texto presente em documentos que foram previamente digitalizados, ou seja, que não foram criados digitalmente de raiz.
Como funciona a nova "visão de raio-X" para PDFs
A magia acontece através de tecnologia de reconhecimento ótico de caracteres (OCR), semelhante à que encontramos, por exemplo, no Google Lens. Anteriormente, o Chrome só conseguia detetar texto em ficheiros PDF que já tivessem essa informação incorporada digitalmente. Os ficheiros resultantes de uma digitalização não possuíam essa "assinatura" de texto, tornando-os ilegíveis para o visualizador do navegador.
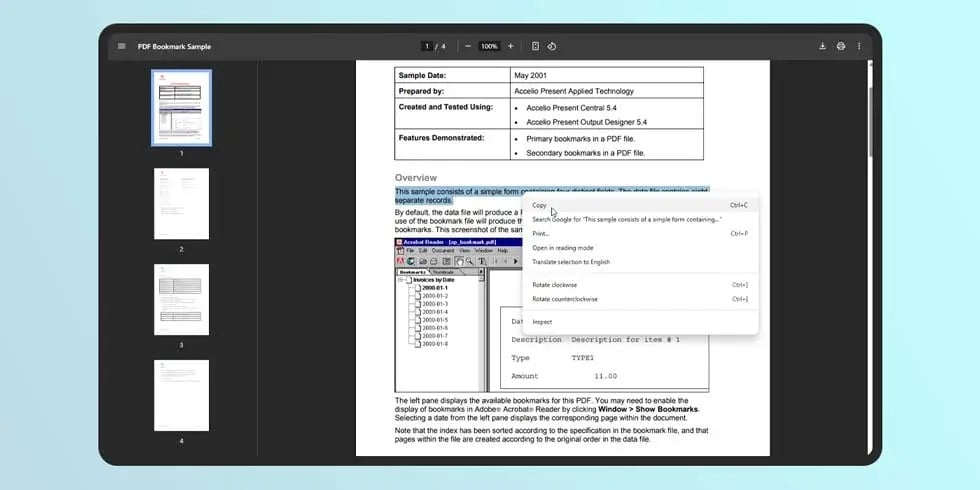
Agora, o Chrome é capaz de analisar a imagem do documento digitalizado e identificar as áreas que correspondem a texto.
Copiar, selecionar e pesquisar: tudo como num PDF normal
Com esta nova capacidade, a interação com PDFs digitalizados no Chrome torna-se indistinguível da experiência com um PDF comum. Os utilizadores podem realçar o texto com o cursor para o copiar para a área de transferência ou utilizar a combinação de teclas "Ctrl + F" para pesquisar termos específicos dentro do documento. Não existe qualquer diferença aparente na interface do visualizador entre um tipo de documento e outro.
Uma evolução natural impulsionada pelo Google Lens
Esta funcionalidade, que esteve inicialmente em testes na versão Chrome Beta, parece estar agora a ser disponibilizada de forma mais alargada aos utilizadores. Considerando a proeminência crescente do Google Lens no ecossistema da Google, e a sua já conhecida capacidade de deteção de texto em imagens, era apenas uma questão de tempo até que esta capacidade fosse integrada de forma mais profunda e útil no próprio navegador. Embora a deteção de texto já fosse uma função existente através do Lens, esta nova implementação no visualizador de PDFs do Chrome sente-se muito mais orgânica e prática para o dia a dia.










Nenhum comentário
Seja o primeiro!