
A OpenAI anunciou uma novidade que promete transformar a forma como os programadores trabalham. Trata-se de uma revelação para pesquisa do GPT-5.3-Codex-Spark, uma versão mais compacta do seu modelo de geração de código, desenhada especificamente para cenários de programação em tempo real.
No mês passado, a empresa já tinha revelado uma parceria com a Cerebras, uma startup focada na criação de sistemas desenhados para acelerar a produção de grandes resultados por inteligência artificial. Na altura, o objetivo declarado era integrar a tecnologia de baixa latência da Cerebras de forma faseada, abrangendo tarefas como a geração de código e de imagens.
O motor por trás de uma velocidade impressionante
A grande estrela deste anúncio é o desempenho alcançado. Alimentado pelo Wafer Scale Engine 3 da Cerebras, o GPT-5.3-Codex-Spark consegue gerar mais de 1000 tokens por segundo, mantendo uma forte capacidade de resposta. Como se trata de uma versão mais pequena, não é esperado que o desempenho atinja a capacidade total do GPT-5.3-Codex, mas a empresa garante que o seu nível de competência se situa entre o GPT-5.3-Codex e o GPT-5.1-Codex-Mini.
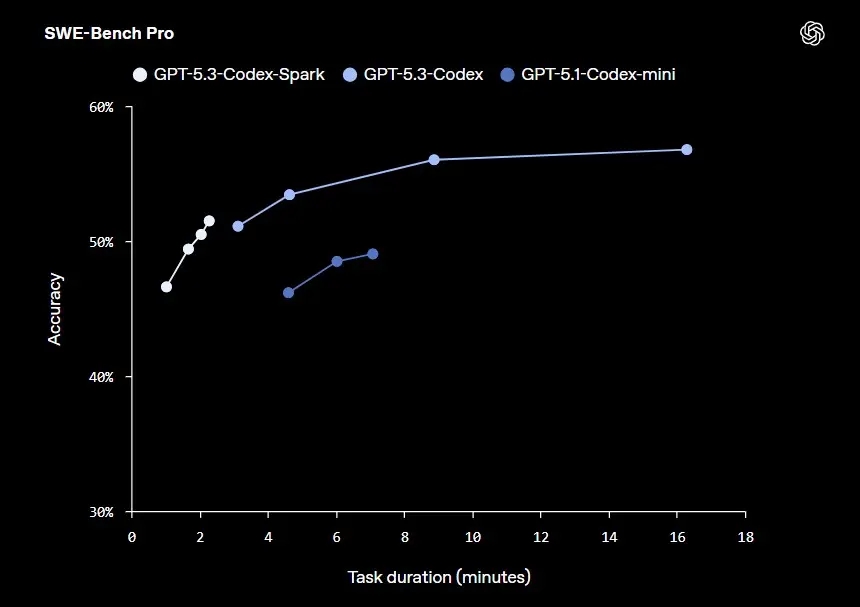
Nesta fase inicial, a ferramenta suporta uma janela de contexto de 128 mil tokens e aceita apenas entradas em formato de texto. Contudo, os planos para o futuro incluem a adição de suporte para modelos maiores, contextos ainda mais extensos e a introdução de capacidades multimodais.
Disponibilidade limitada aos utilizadores Pro
Se estás interessado em testar esta velocidade vertiginosa, o lançamento está limitado aos subscritores do plano ChatGPT Pro. Para teres acesso a este modelo de latência ultrabaixa, precisas de atualizar para as versões mais recentes da aplicação Codex, da interface de linha de comandos (CLI) e da extensão para o VS Code.
É importante notar que o modelo terá os seus próprios limites de taxa de utilização, os quais não irão contar para os teus limites padrão. No entanto, a empresa alerta que, caso existam picos de procura, o acesso poderá ser ainda mais restrito ou os utilizadores poderão ser colocados em filas de espera para manter a fiabilidade do sistema. Paralelamente, uma pequena seleção de parceiros de design já tem acesso através da API, para que a empresa possa entender como os programadores querem integrar a ferramenta noutros produtos e serviços.
Apesar desta forte aposta, os GPUs continuam a ser a principal plataforma de computação para as linhas de treino e execução geral da empresa. A tecnologia da Cerebras foi posicionada como a melhor opção especificamente para tarefas do Codex que exigem uma latência extremamente baixa. Para o futuro, as duas tecnologias poderão ser combinadas numa única tarefa para alcançar o melhor desempenho geral, segundo a informação partilhada pela OpenAI.














Nenhum comentário
Seja o primeiro!