
A Anthropic revelou o seu mais recente modelo de inteligência artificial, o Claude Mythos, que se destaca por conseguir identificar milhares de vulnerabilidades do tipo Zero Day nos principais sistemas operativos e navegadores web. De acordo com o Tom's Hardware, a versão de pré-visualização desta inteligência artificial focada em cibersegurança está a demonstrar capacidades de deteção muito superiores às gerações anteriores.
A evolução da tecnologia tem sido notória, passando de assistentes básicos para ferramentas cada vez mais complexas. O novo modelo integra o Project Glasswing, uma iniciativa onde a empresa colabora com gigantes tecnológicas como a Google, a Microsoft e a NVIDIA para testar e proteger infraestruturas e serviços críticos. Embora seja classificado como um modelo de propósito geral, o seu grande foco foi desenhado diretamente para o setor da segurança informática.
O salto no desenvolvimento de exploits e segurança
Um dos dados mais relevantes deste modelo é a sua capacidade de transformar vulnerabilidades complexas em exploits funcionais, algo que não era possível com a mesma eficácia no passado. Nos testes realizados, o Mythos alcança uma taxa de sucesso de 72,4% na criação de exploits, conseguindo ainda assumir o controlo do sistema em 11,6% das vezes, com apenas 16% de falhas.
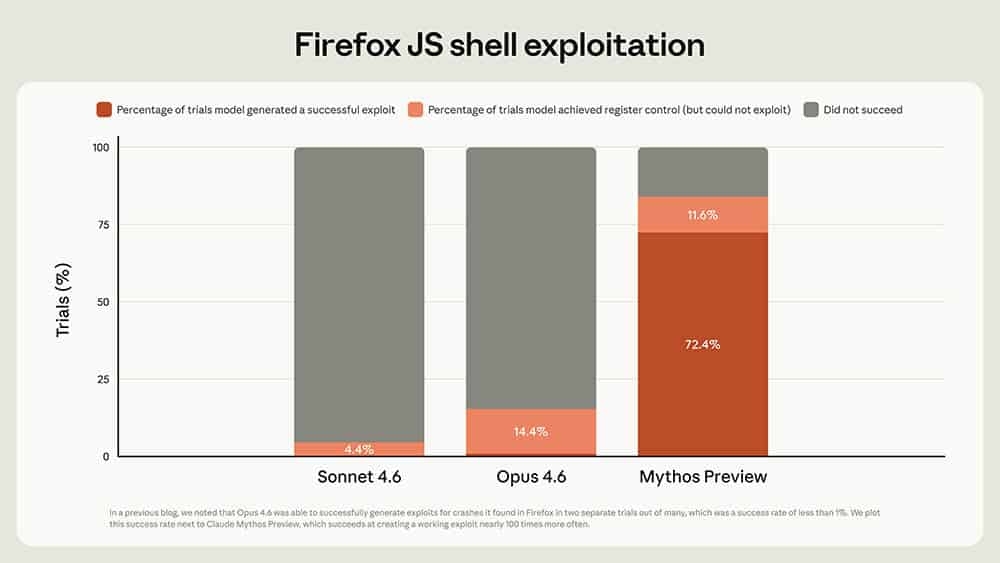
Quando comparado com os seus antecessores, as diferenças saltam à vista. O Claude Opus 4.6 registava 85,6% de falhas nas mesmas tarefas, conseguindo apenas 14,4% de controlo, enquanto o Sonnet 4.6 falhava em 95,6% das tentativas. No que toca à reprodução de vulnerabilidades de cibersegurança, a nova versão atinge os 83,1% de sucesso, superando claramente os 66,6% do Opus 4.6.
Desempenho superior em raciocínio e agentes autónomos
Para além da vertente da cibersegurança, o modelo apresenta melhorias noutras avaliações de peso. No teste de agentes autónomos SWE-bench Pro, o Mythos regista 77,8% de sucesso contra os 53,4% do Opus. A tendência mantém-se no SWE-bench Multimodal, onde atinge 59% face a 27,1%, e no SWE-bench Verified, com uma marca de 93,9%.
Em testes de capacidade de raciocínio lógico como o Humanity's Last Exam, o modelo alcança 56,8% de eficácia, suplantando os 40% do Opus 4.6, ganhando também em avaliações de navegação e sistemas como o BrowseComp e o OSWorld. Após recentes repercussões relacionadas com o uso de sistemas da empresa pelo exército dos Estados Unidos, a capacidade deste modelo em detetar e transformar brechas de segurança sublinha o seu poder, deixando a porta aberta para avaliar como estas ferramentas vão influenciar a dinâmica entre a defesa e os ataques no espaço digital.














Nenhum comentário
Seja o primeiro!